We’ve seen a lot of trends in high-tech industry over the 30+ years for which ECM have been working with the best and brightest candidates and companies. Data science, and subsequently machine learning, have been two of the hottest topics we’ve encountered – there is a huge amount of interest in these, from both candidates and companies in the field.
The confusing thing for people trying to understand these areas is that the same terminology is used not only to describe variations on a theme but also in some cases to encompass or exclude larger portions of the field than one might imagine. This is true for details published by companies, described by universities and professionals, and even topics cited in major publications.
It’s easiest to understand this as a diagram:
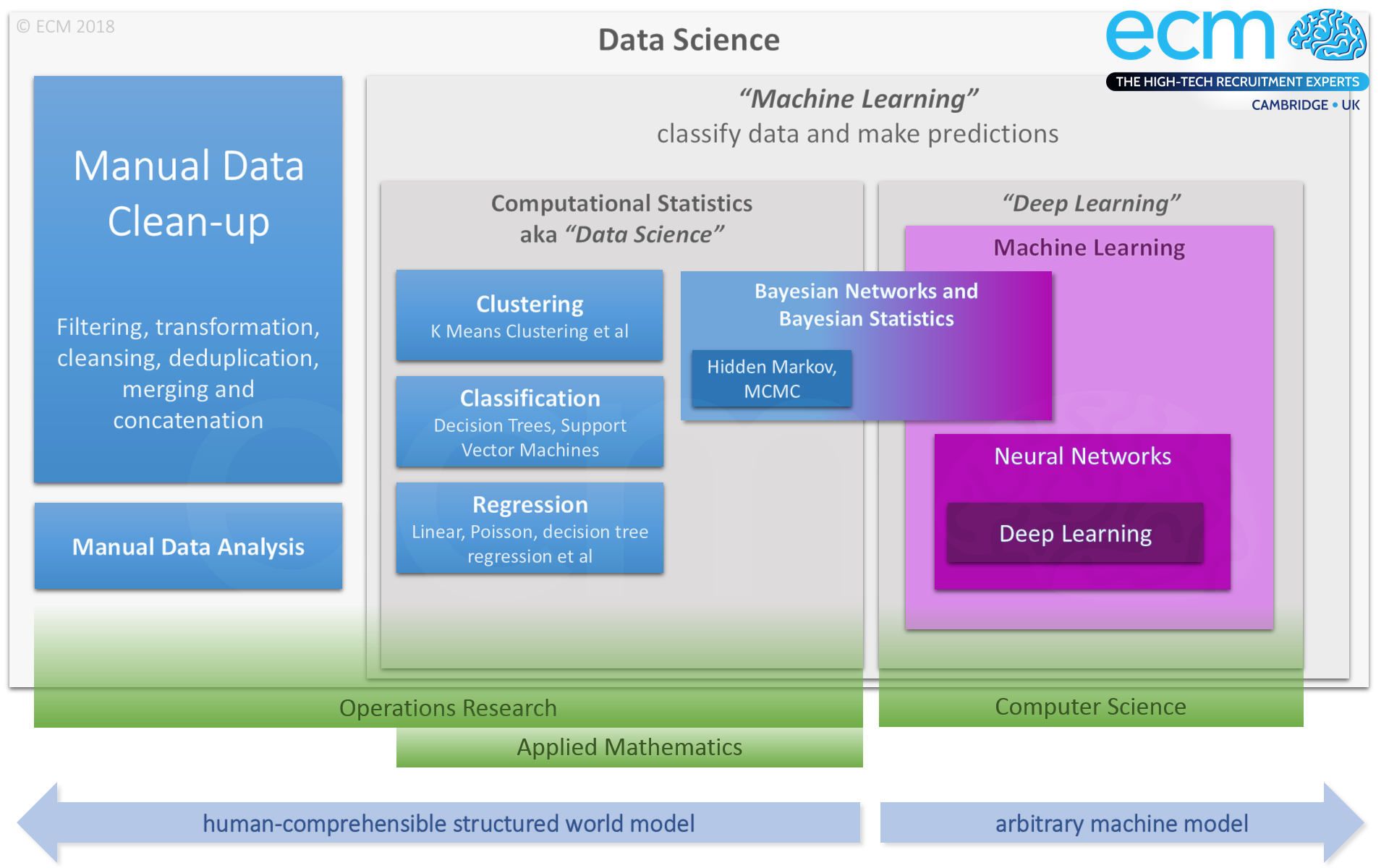
(A larger version of this diagram is available for download. Depending on your web browser, clicking the link may save it to your Downloads without telling you it's done so.)
This is a view of the overall field of data science. Here, quotes around “machine learning” or “deep learning” indicate common usage; unquoted terms are (in our subjective view) more technical / specific definitions from the perspective of people in those fields. You’ll encounter both, so it’s worth bearing in mind the differences. But do note, everyone’s perspective is different – and that’s a good thing – and language is always evolving. This makes it hard for those of us with a technical background as we’re used to precise terminology - but broader definitions help to advance the edges of the field and make subjects more approachable and inclusive.
In part one, we'll discuss data science - in part two we'll discuss machine learning, and in part three we'll touch on big data.
Data Science: The Broad View
From a certain perspective, the field of data science can be seen as encompassing the totality of data processing, from initial cleanup and reasoned or intuitive analysis through to statistical work and (where applicable) the application of machine learning technologies.
The goal in every case is to answer a question relevant to a business or group of people, and the answer (since it is often based on statistics) usually comes in the form of a percentage or probability. Sometimes the question is known at the start; sometimes the data is known but the goal is to explore what can be learned from this data that may be of value to the business and so the question is derived during the analysis. This is increasingly common as the excitement around the fields of data science and machine learning has swept across the business landscape; companies realise they have vast quantities of untapped data on hand, and feel they should be making use of it. These conditions have given rise both to specialist consultancies in these fields, and to domain experts with a variety of scientific backgrounds, all contributing to answering these questions for different kinds of data.
Data Science: The Statistical View
Some people view data science less broadly, and would be more likely to name the field as a whole as data analysis or data modelling (or even data processing). They might use the term data science to refer to activities which fall more strictly into the fields of computational statistics and applied mathematics. This is the exciting bit of data science from a mathematical standpoint, and it’s effectively the fulcrum, i.e. the greatest point of leverage, for statistical methods.
These methods fall into three primary areas, with related goals:
- Clustering – grouping data by similarity
- Classification – categorising data
- Regression – quantifying and predicting relationships
These are further supported by mathematical techniques which allow a “best” fit to be made to a curve or series of curves intended to approximate the equation (model) describing a set of data points along various axes. Techniques such as Markov Chain Monte Carlo apply to this category.
There is also substantial overlap between this view of data science, and the field of operations research (OR), also known as operational research, which has comparable goals and overlapping methods.
A Career As A Data Scientist
As the field is still developing, data scientists frequently come from a wide variety of backgrounds and there is no prescribed route into the field. At ECM we find data scientists often have a strong background in maths or physics, and especially have knowledge of statistics and a real enthusiasm for working directly with data.
There are some things worth knowing if you’re considering a career in data science. If you ask any data scientist working commercially, a substantial amount of their time (indeed the vast majority of it, for many people) is spent on the data to clean it and prepare it ready for analysis. Data must be filtered and transformed, rogue values eliminated, duplicates removed, sources merged and combined. This normalisation process is critical for the success of later stages, whose conclusions will otherwise be incorrect. Given each data source (and even sometimes, each data set) is different, and requires an intuitive understanding of the data and the problem, this stage remains largely a manual task; though often data scientists will write ad hoc scripts and transformations to help them once they start to see patterns.
After this critical stage, work diverges depending on the kind of data scientist one speaks to. People from a statistical background will often be building statistical models, or writing statistical code from first principles. Others will be working with data engineers: those being people with a combined mathematical and software development skillset whose role it is to provide tools to allow data scientists to do their work (and this is far from a purely supporting role; a skilled data engineer has just as much of a vital role to play in that process). Given the quality and availability of pre-existing platforms, libraries and toolkits, there are also a large number of data scientists whose work involves taking advantage of these, understanding their foibles and quirks, and directing the process of analysis by shepherding data through the right tools. This isn’t as simple as it might sound: in many tools just as complex a model can be built by the data scientist as would be built from first principles and it’s just as important that the basis of that model is correct.
Register with ECM Jobs in Data Science
Continue reading about machine learning in part two and about big data in part three.


